
AI Accent Guesser: This technology, capable of identifying accents in speech, presents a fascinating intersection of artificial intelligence, linguistics, and ethical considerations. Its development relies on sophisticated machine learning models trained on vast datasets of spoken language, allowing for the classification of accents based on subtle phonetic variations. However, the accuracy and ethical implications of these systems are crucial aspects that demand careful examination.
The core functionality involves analyzing audio input, extracting relevant features like pitch, rhythm, and intonation, and comparing these against a model’s learned representations of different accents. This process is far from simple, encountering challenges like noise interference, code-switching, and the inherent variability within and between accents. Understanding these limitations is vital to responsible development and deployment.
AI Accent Guessers: A Deep Dive
AI accent guessers are sophisticated systems capable of identifying the accent of a speaker based on their audio input. This technology leverages advancements in machine learning and signal processing to analyze subtle variations in pronunciation, intonation, and rhythm. This article delves into the underlying technology, data considerations, ethical implications, applications, and limitations of AI accent guessers.
Underlying Technology of AI Accent Recognition, Ai accent guesser
AI accent recognition systems rely on a combination of signal processing techniques and machine learning models. Signal processing extracts relevant features from the audio input, such as spectral characteristics and prosodic features (intonation, rhythm). These features are then fed into machine learning models for accent classification.
Various machine learning models are employed, including Hidden Markov Models (HMMs), Support Vector Machines (SVMs), and deep learning architectures like Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). Deep learning models, particularly those based on RNNs and CNNs, have demonstrated superior performance in recent years due to their ability to learn complex patterns from large datasets.
Feature extraction techniques play a crucial role in the accuracy of accent identification. Common techniques include Mel-Frequency Cepstral Coefficients (MFCCs), Linear Predictive Coding (LPC), and Perceptual Linear Prediction (PLP). The choice of feature extraction method depends on the specific characteristics of the audio data and the machine learning model used.
The process of accent guessing can be visualized as follows:
Flowchart: Accent Guessing from Audio Input
1. Audio Input: Raw audio recording is obtained.
2. Preprocessing: Noise reduction, silence removal, and other necessary steps are performed.
3.
Feature Extraction: Relevant acoustic features (MFCCs, LPC, etc.) are extracted.
4. Feature Normalization: Features are scaled or normalized to improve model performance.
5. Accent Classification: A trained machine learning model classifies the input based on extracted features.
6. Output: The predicted accent is outputted.
AI accent guessers are fascinating examples of machine learning; their ability to analyze speech patterns is quite impressive. Consider the precision needed, similar to predicting the outcomes for teams in the 2024-25 College Football Playoff: What’s next for the eliminated , where subtle shifts in performance can drastically alter a season’s trajectory. Returning to AI accent guessers, further advancements could lead to even more nuanced and accurate predictions about a speaker’s background.
Data and Accuracy of AI Accent Guessers
The accuracy of AI accent guessers is heavily dependent on the quality and diversity of the training data. Datasets commonly used include publicly available speech corpora, such as LibriSpeech and Common Voice. However, these datasets often suffer from limitations such as class imbalance (some accents are underrepresented) and lack of diversity in terms of speaker demographics and recording conditions.
Several factors influence the accuracy of accent identification, including audio quality, speaker variability, background noise, and the complexity of the accent itself. Moreover, biases present in the training data can significantly impact the results, leading to inaccurate or discriminatory outcomes. For instance, if a dataset predominantly features speakers from a particular region, the model may struggle to accurately identify accents from underrepresented regions.
Below is a table illustrating a hypothetical comparison of accuracy across different AI accent guessers and languages (note: these figures are illustrative and may not reflect the actual performance of any specific system):
| AI Accent Guesser | British English | American English | Australian English |
|---|---|---|---|
| Guesser A | 92% | 88% | 85% |
| Guesser B | 89% | 91% | 87% |
| Guesser C | 90% | 86% | 90% |
Ethical Considerations of AI Accent Guessers
The use of AI accent guessers raises several ethical concerns. The potential for misuse in areas like law enforcement or hiring processes is a major concern. Inaccurate or biased results can lead to unfair or discriminatory outcomes. For example, a flawed system might incorrectly identify a non-native speaker’s accent as indicative of lower intelligence or competence.
Scenarios where misuse could lead to discrimination include:
- Law enforcement using the technology to profile individuals based on their accent.
- Hiring managers using the technology to unfairly screen out candidates based on perceived accent.
- Educational institutions using the technology to unfairly assess language proficiency.
Best practices for responsible development and deployment include:
- Ensuring diverse and representative datasets.
- Regularly auditing for bias and inaccuracies.
- Transparency about the technology’s limitations and potential biases.
- Implementing robust safeguards to prevent discriminatory outcomes.
Applications and Future Trends of AI Accent Guessers

AI accent guessers have several real-world applications, including language learning, speech synthesis, and accessibility tools. They can help language learners identify and improve their pronunciation, provide personalized feedback, and create more natural-sounding synthetic speech.
Future developments may include improved accuracy, robustness to noise, and the ability to handle code-switching and dialectal variations. AI accent guessers can play a significant role in improving accessibility for language learners and bridging communication gaps.
AI accent guessers are fascinating; they analyze speech patterns to pinpoint origins. I was thinking about this while reading a humorous anecdote about a blind date – the description, found in this article, Blind date: ‘He looked like a cross between Andrew Garfield and my , made me wonder if an AI could guess his accent based solely on his description! It highlights how much subtle information we process, even without considering voice.
Returning to AI accent guessers, the technology continues to improve, offering intriguing possibilities.
Potential future applications beyond current uses:
- Personalized language learning platforms.
- Improved voice assistants with accent-aware capabilities.
- Real-time translation systems that adapt to different accents.
- Accessibility tools for individuals with speech impairments.
Technical Aspects and Limitations of AI Accent Guessers
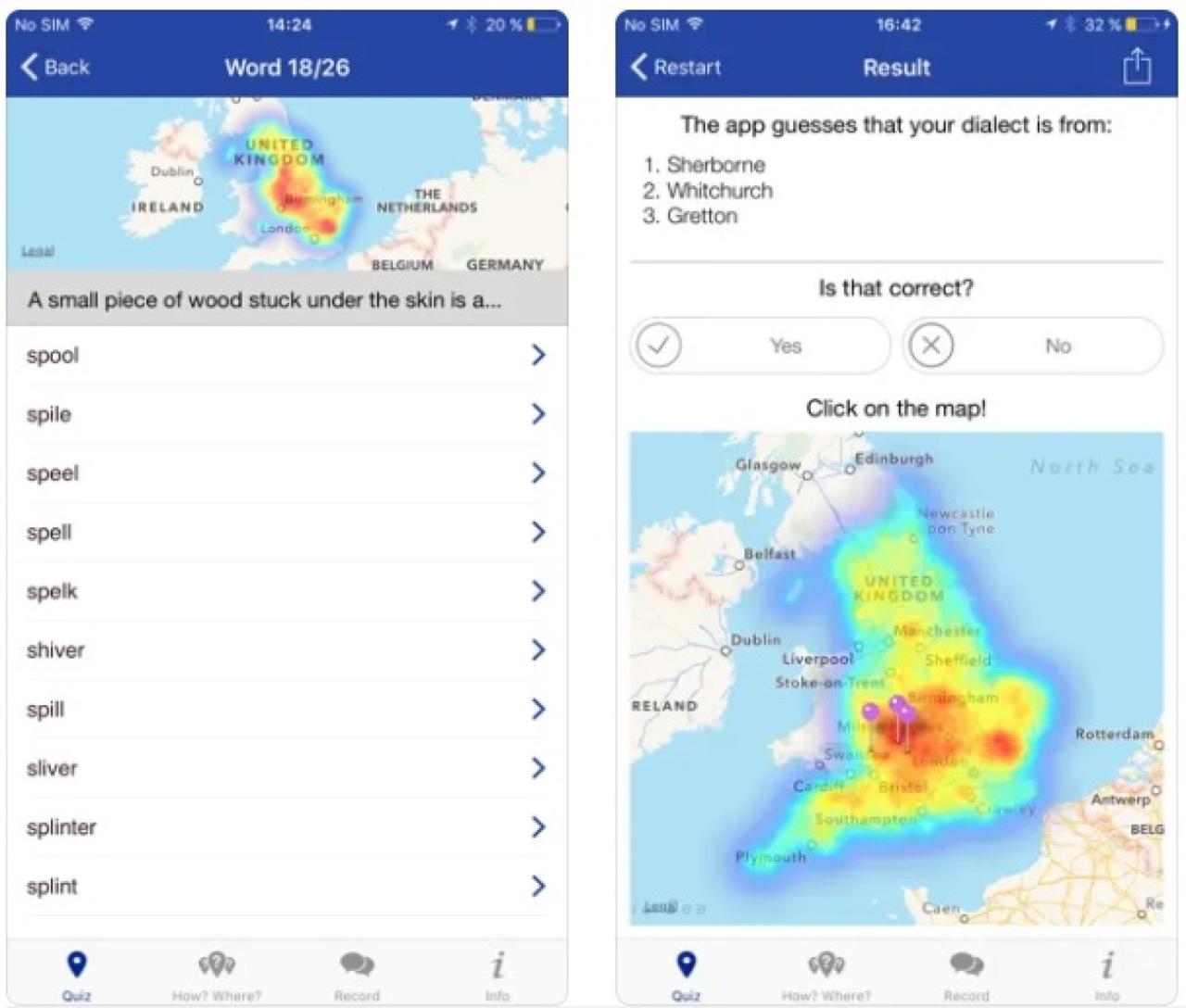
Accurately identifying accents in noisy audio environments remains a significant challenge. Background noise, reverberation, and other audio artifacts can interfere with the extraction of relevant acoustic features, leading to reduced accuracy. Current AI accent guessers also struggle with handling code-switching (mixing languages within a single utterance) and dialectal variations, which introduce additional complexity.
Examples of scenarios where an AI accent guesser might fail include:
- A speaker with a strong regional dialect that is not well-represented in the training data.
- A speaker who code-switches between multiple languages.
- An audio recording with significant background noise or poor audio quality.
Different audio preprocessing techniques, such as noise reduction filters and spectral normalization, can significantly affect the performance of AI accent guessers. Careful selection and optimization of these techniques are crucial for achieving optimal accuracy.
Illustrative Examples of Accent Identification

In a scenario where an AI accent guesser correctly identifies an accent, the system might analyze the audio input and identify specific phonetic features characteristic of that accent. For example, the model might detect a distinct rhythm pattern, specific vowel pronunciations, or intonation contours associated with a particular regional accent, leading to a correct classification. The model’s reasoning would involve a combination of feature extraction and classification processes.
Conversely, in a scenario where the AI accent guesser incorrectly identifies an accent, the error might stem from several factors. The audio might contain significant background noise masking key phonetic features, the speaker might have a unique pronunciation that deviates significantly from the training data, or the model itself might contain biases. The model’s reasoning, even if incorrect, would still involve analyzing the features and applying its classification rules, highlighting the limitations of the model’s training and generalization capabilities.
The audio characteristics of three distinct accents (British English, American English, Australian English) relevant to an AI accent guesser would include variations in vowel sounds (e.g., the pronunciation of “bath” and “caught”), intonation patterns (e.g., rising intonation at the end of declarative sentences in some accents), and rhythmic features (e.g., stress patterns on syllables).
AI accent guessers represent a powerful yet complex technology. While offering potential benefits in fields like language learning and accessibility, their deployment requires careful consideration of ethical implications and potential biases. Addressing these concerns through responsible development and transparent use is crucial to ensuring the technology serves a positive purpose without perpetuating discrimination or misrepresentation. The ongoing refinement of these systems and exploration of their applications promise exciting advancements, but responsible implementation remains paramount.
Popular Questions
How accurate are AI accent guessers?
Accuracy varies significantly depending on factors like the dataset used for training, the clarity of the audio, and the complexity of the accent. While some systems achieve high accuracy in specific contexts, generalizability across diverse accents and noisy environments remains a challenge.
What are the privacy implications of using AI accent guessers?
The use of voice data raises significant privacy concerns. It’s crucial that data collection and usage comply with relevant regulations and ethical guidelines, ensuring user consent and data anonymization where appropriate.
Can AI accent guessers identify dialects within an accent?
Current AI accent guessers often struggle with distinguishing finer-grained variations like dialects. This limitation stems from the complexities of dialectal variation and the need for more comprehensive datasets representing these nuances.